引入
本次实验我们研究的是人口增长问题。人类作为真正意义上的食物链顶端,人口增长的结果会给一个国家,一个地区,甚至整个世界的运作带来很大的影响。是自然环境,资源,国防,劳动力等宏观问题变化的主要影响因素。认识人口数量的变化过程,建立数学模型描述人口的发展规律,做出较准确的增长预测,是制定积极、稳妥的人口政策的前提。所以研究人口的变化趋势是很有必要的。但是人口的变化不是一成不变的,它到底是符合怎么样的趋势在变化,这是本次实验的研究要点。本次使用的数据是美国从1790年到2000年每隔10年取样总共22年的数据。根据课本的指导,按照趋势匹配精度的增加,一共有四个模型(指数增长模型一,指数增长模型二,改进的指数增长模型和logistic模型)。本次实验所用的工具软件为MATLAB。
(注:
- 本文的思路是完全按照《数学模型》第五版的思路进行的,数据略有不同,是因为这些数据是笔者亲自实验得出的结果。
- 本文所用的数据同样来自《数学模型》第五版中人口增长模型提供的美国从1970年到2000年中每隔十年取一个的数据。)
指数增长模型一
模型假设
在最初的模型上,我们假设人口的年增长率在k年内是不会发生变化的。也没有任何的外力因数去影响人口的增长。
模型构建
如果已知今年的人口为,年增长率为r,那么预测k年后的人口为:
模型求解
使用MATLAB工具进行拟合,我们首先将该方程转化为线性方程。具体方法是在方程左右两边取对数,得
再通过变量替换,最后通过数据拟合求出对应的一阶线性方程,最后再将变量替换回来。
MATLAB代码如下:
1 | clc |
模型分析
通过图像我们可以看出,这种将增长率确定为不变的方法的拟合效果并不是非常好。虽然增长率的误差变化不大,但是最终得到的原方程拟合效果在18年后却完全脱离了实际情况。为了能够解决这种情况,接下来的指数增长模型二是将指数部分单独拟合。
指数增长模型二
模型假设
在这个模型中,我们对于人口增长的增长率分离出来单独进行拟合,同样的,本模型不考虑自然资源的限制对人口的增长的影响。
模型构建
当考察一个国家或一个较大地区的人口随时间延续而变化的规律时,为了利用微积分这一数学工具,可以将人口看做连续时间t的连续可微函数x(t),记初始时刻(t=0)的人口为,假设单位时间人口增长率为常数r,rx(t) 就是单位时间内x(t)的增长率,于是得到 x(t) 满足的微分方程和初始条件
将该公式进行变量分离可以得出
当x>0时,人口将按指数规律无限增长。
模型求解
对于得到的常微分方程是比较容易人工得出 x(t) 的模型的,所以我们进行人工计算之后代入到MATLAB,直接使用美国1970年的总人口3.9(单位:百万),r 是直接求取这21年的增长率平均值得到的。
MATLAB代码如下:
1 | clc |
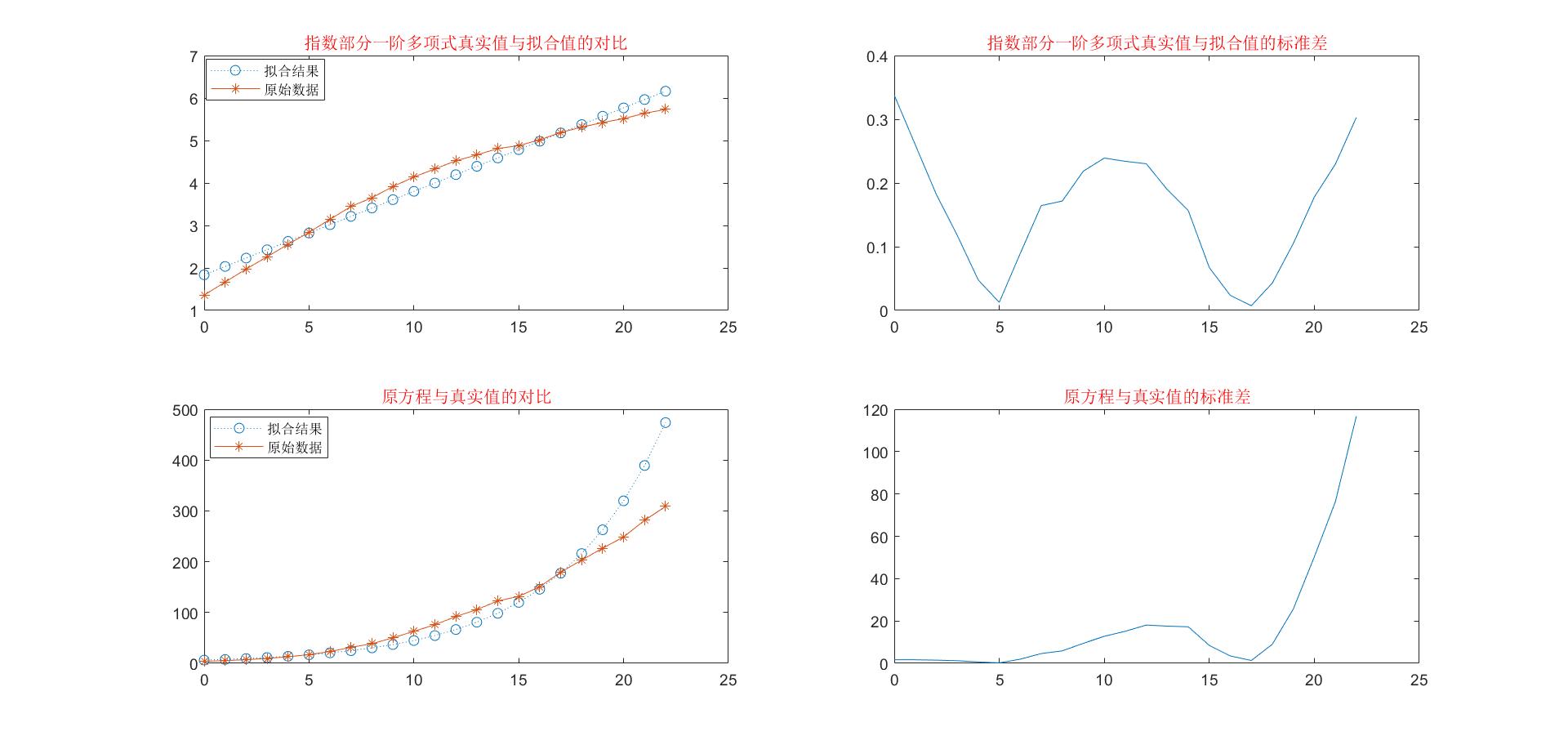
模型分析
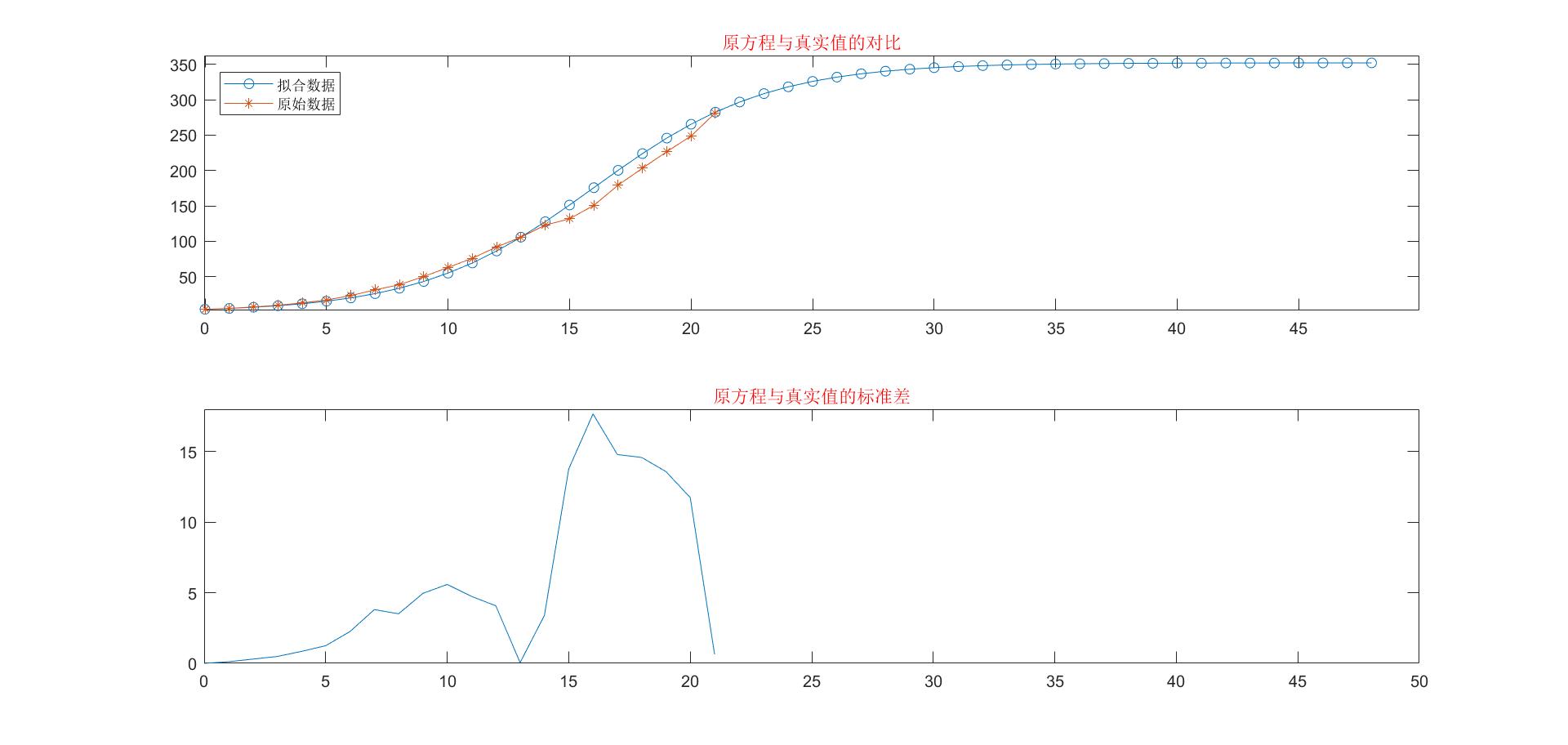
从标准差图像中我们可以看出:该模型比指数增长模型一的标准差要小很多,要更加贴合实际,但是在14年左右还是出现较大的误差,然后也存在在20年之后模型完全脱离实际的情况。所以为了能够更好地贴合实际,我们将指数部分再一次进行优化。
改进后的指数增长模型
建模假设
由于增长率不是一成不变的,所以我们对之前的模型进行重新的修改,将指数部分进行线性拟合,同时还是不考虑自然资源限制对人口增长的影响。
模型构建:
我们将指数增长模型二改写为
其中,令r为一个线性函数
模型求解
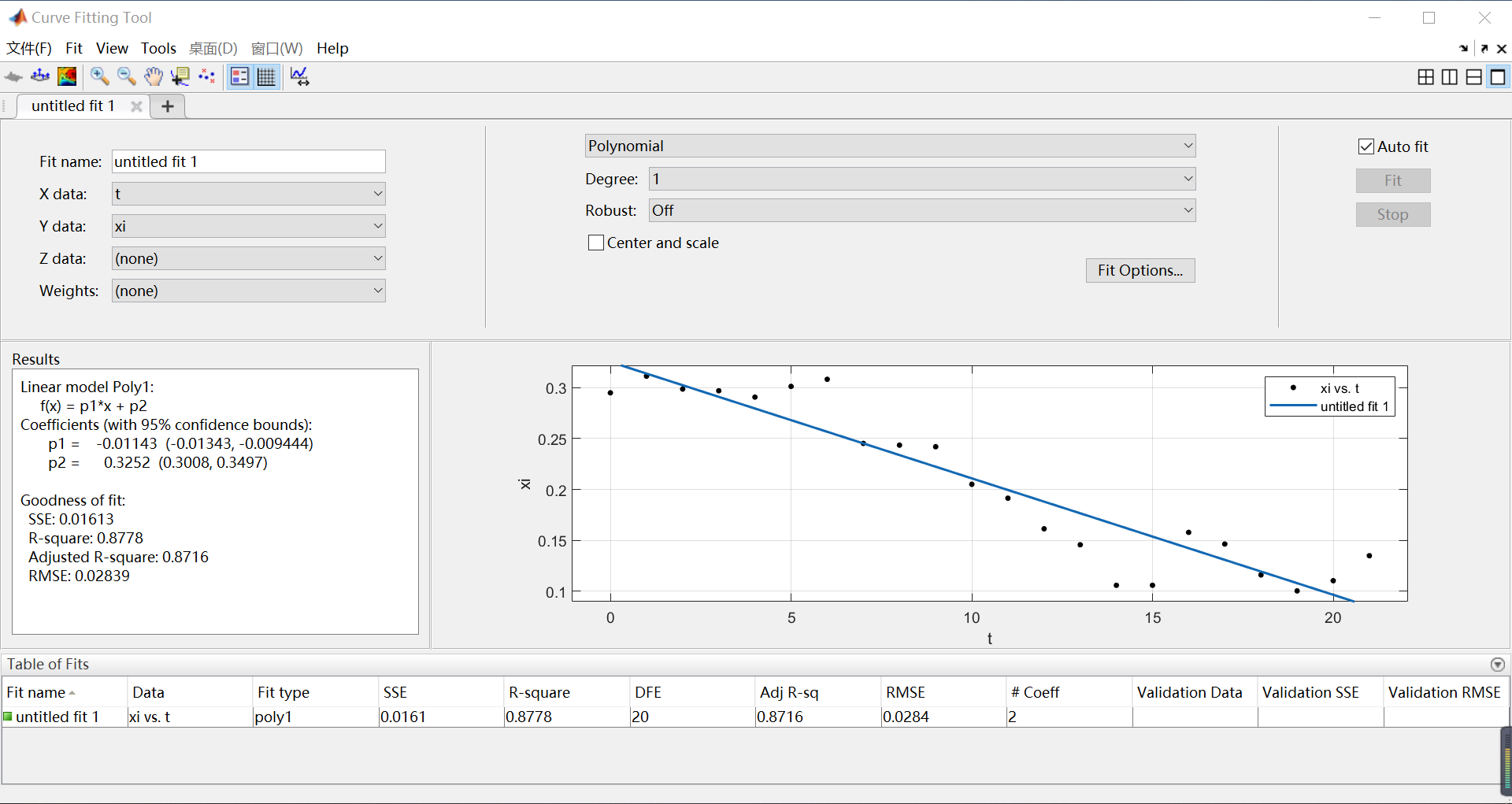
使用MATLAB中的Curve Fitting Tool进行线性拟合得出
将该数据带入到MATLAB中常微分方程的求解
1 | clc |
结果如下图:
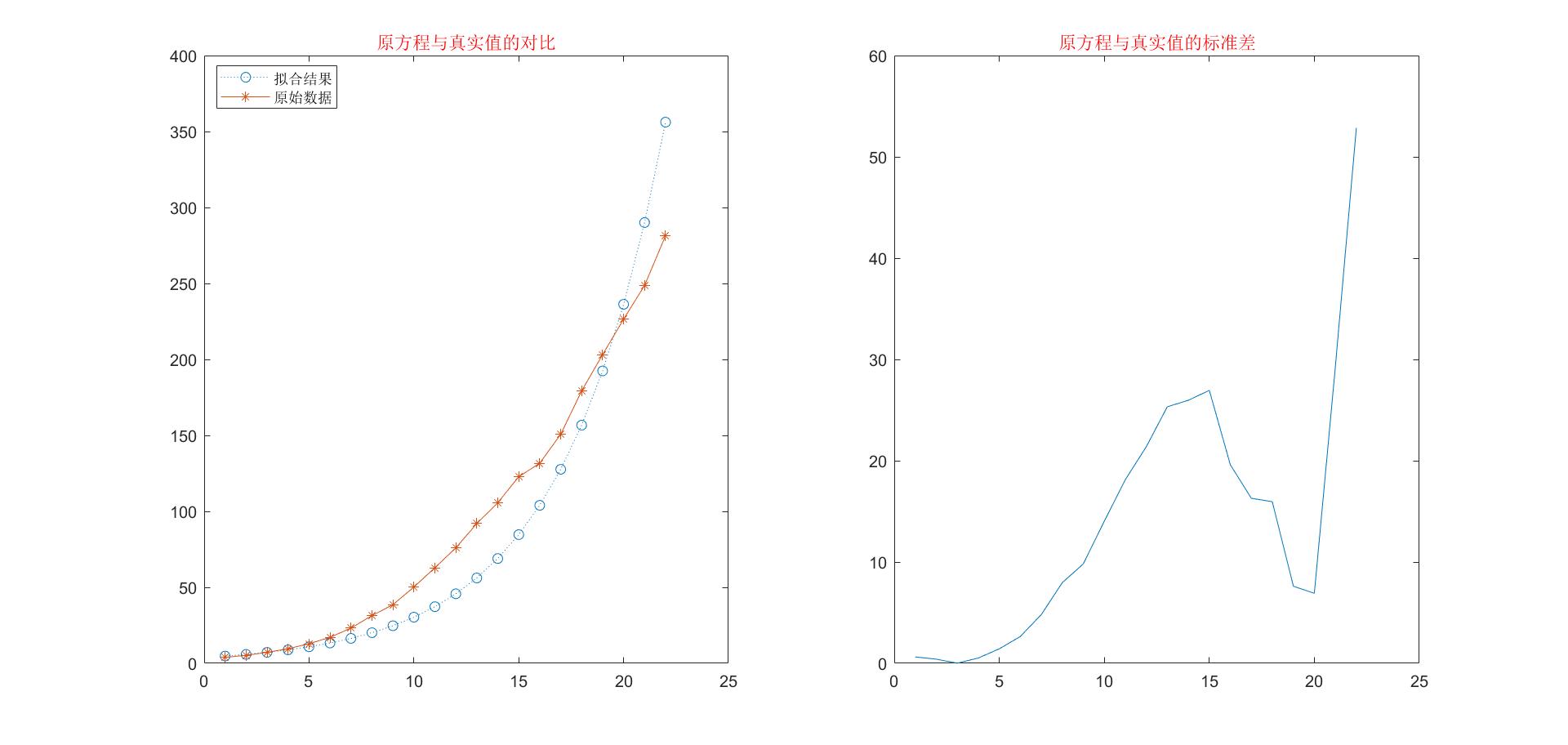
模型分析
从该模型的结果我们可以看出,拟合数据和实际数据的标准差已经缩减的很小了,从左图中也可以很直观地看出两条曲线非常接近。虽然改进的指数增长模型考虑到增长率随时间的变化,计算结果有所改善,但是它没有反应增长率下降的原因,增长率行数形式也呈现出不确定性,给应用带来不便,为了建立更加符合实际情况的人口增长模型,必须考虑人口下降的机理,修改原来的模型假设。
至此,三个模型的结果如下:
| 年份 | 实际人口/百万 | 指数增长模型 (方法一) | 指数增长模型 (方法二) | 改进的指数 增长模型 |
|---|---|---|---|---|
| 1790 | 3.9 | 6.3 | 4.8 | 3.9 |
| 1800 | 5.3 | 7.7 | 5.9 | 5.4 |
| 1810 | 7.2 | 9.3 | 7.2 | 7.3 |
| 1820 | 9.6 | 11.3 | 8.9 | 9.8 |
| 1830 | 12.9 | 13.8 | 10.9 | 13.1 |
| 1840 | 17.1 | 16.8 | 13.4 | 17.2 |
| 1850 | 23.2 | 20.4 | 16.4 | 22.4 |
| 1860 | 31.4 | 24.9 | 20.1 | 28.7 |
| 1870 | 38.6 | 30.3 | 24.7 | 36.5 |
| 1880 | 50.2 | 36.9 | 30.4 | 45.9 |
| 1890 | 62.9 | 44.9 | 37.3 | 57.0 |
| 1900 | 76 | 54.6 | 45.8 | 70.0 |
| 1910 | 92 | 66.4 | 56.2 | 85.0 |
| 1920 | 105.7 | 80.9 | 69.0 | 102.0 |
| 1930 | 122.8 | 98.4 | 84.7 | 121.1 |
| 1940 | 131.7 | 119.8 | 104.0 | 142.1 |
| 1950 | 150.7 | 145.8 | 127.7 | 164.8 |
| 1960 | 179.3 | 177.4 | 156.7 | 189.1 |
| 1970 | 203.2 | 215.9 | 192.4 | 214.4 |
| 1980 | 226.5 | 262.8 | 236.3 | 240.3 |
| 1990 | 248.7 | 319.9 | 290.1 | 266.4 |
| 2000 | 281.4 | 389.3 | 356.2 | 291.9 |
| 误差平方和/10000 | 2.1319 | 1.5756 | 0.1311 |
logistics模型
建模假设
关于人口增长到一定数量之后增长率下降的原因,查阅资料知道:自然资源、环境条件等因数对人口增长起着阻滞作用,并且随着人口的增加,阻滞作用越来越大。所以才产生了logistic模型。
模型构建
资源和环境对人口增长的阻滞作用体现在对增长率 r 的影响上,使 r 随着人口数量 x 的增加而下降。将 r 表示为含 x 的函数 r(x) ,并且取既简单又方便应用的线性减函数 。为了赋予增长率函数 r(x) 中系数a,b 以实际含义,引入两个参数:
内禀增长率r r是(理论上)x=0的增长率,即r(0)=r,于是a=r;
人口容量 是资源和环境所能容纳的最大人口数量,当x=时人口不再增长,即,得到
由此导出的增长率函数为。用 r(x) 代替指数增长模型二中的r,得到
方程右端的因子体现人口自身的增长趋势,因子则体现了资源和环境对人口增长的阻滞作用。显然 x 越大,前一因子越大,后一因子越小,人口增长是两个因子共同作用的结果。
模型求解
我们将常微分方程通过变量分离可以得到
其中为参数。
估计参数方法一
将常微分方程改写为
对于右端的 x 用线性最小二乘法估计 直接采用原始数据。
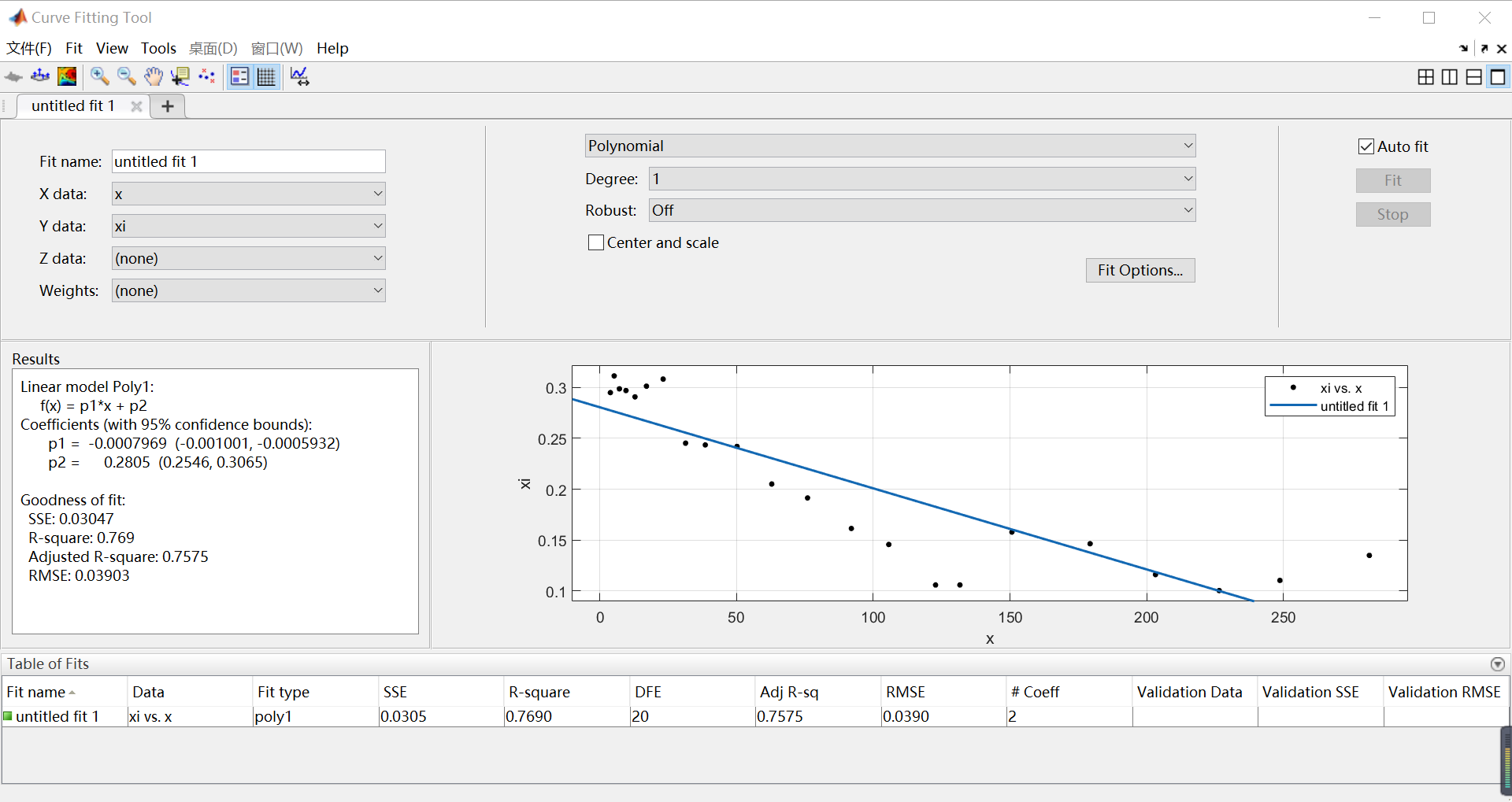
图中 x 为人口数量,xi为增长率。通过Curve Fitting Tool线性拟合,我们可以得到,通过 ,得到,再取得到模型。具体MATLAB代码如下:
1 | clc |
估计参数方法二
直接使用人口数据和非线性最小二乘法估计。
得出,代入原方程得出模型。
具体代码如下:
1 | clc |
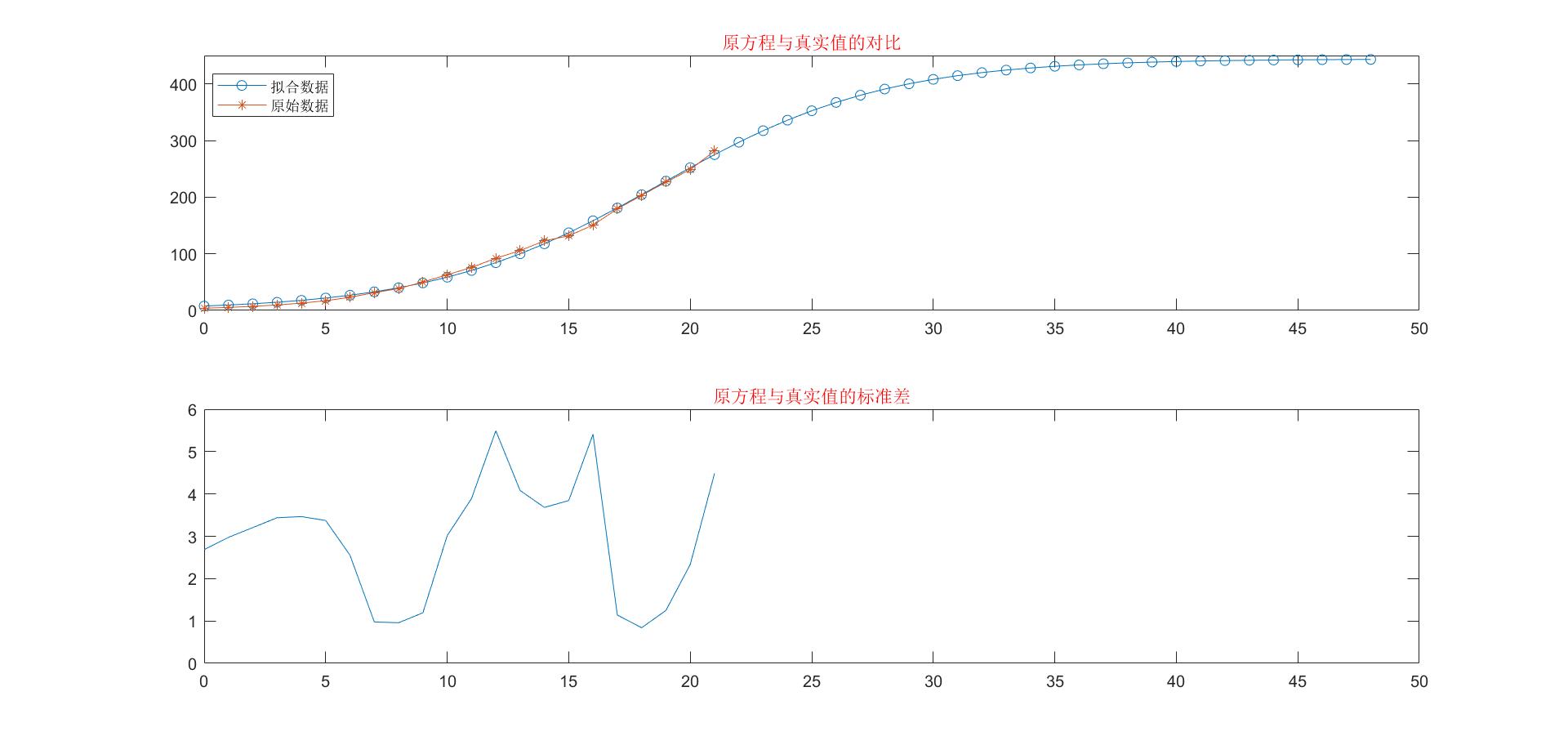
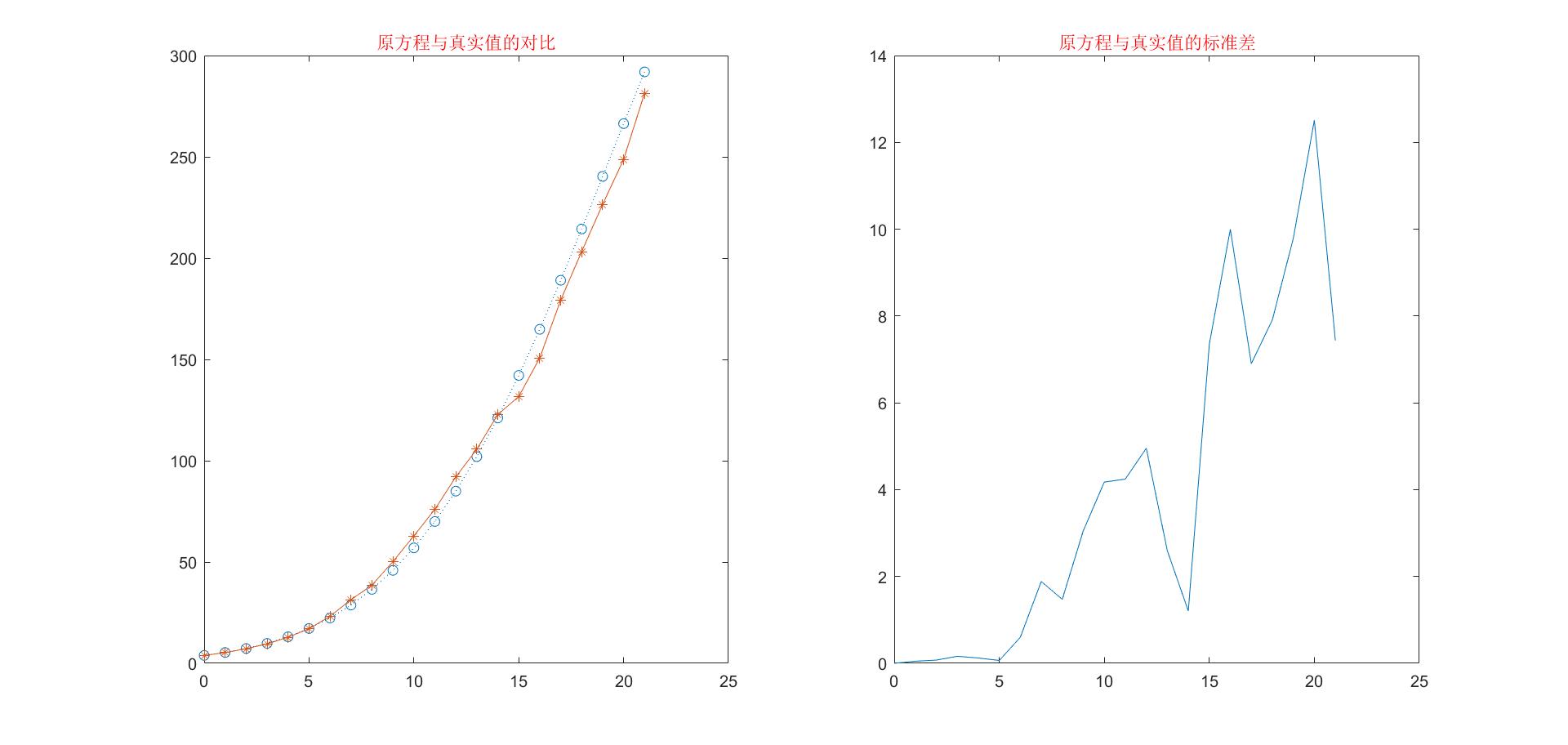
两个方法的拟合结果如下图:
| 年份 | 实际人口/百万 | 方法一 | 方法二 |
|---|---|---|---|
| 1790 | 3.9 | 3.9 | 7.7 |
| 1800 | 5.3 | 5.1 | 9.5 |
| 1810 | 7.2 | 6.8 | 11.7 |
| 1820 | 9.6 | 8.9 | 14.5 |
| 1830 | 12.9 | 11.7 | 17.8 |
| 1840 | 17.1 | 15.3 | 21.9 |
| 1850 | 23.2 | 20.0 | 26.8 |
| 1860 | 31.4 | 26.0 | 32.8 |
| 1870 | 38.6 | 33.6 | 40.0 |
| 1880 | 50.2 | 43.2 | 48.5 |
| 1890 | 62.9 | 55.0 | 58.6 |
| 1900 | 76 | 69.3 | 70.5 |
| 1910 | 92 | 86.2 | 84.2 |
| 1920 | 105.7 | 105.8 | 99.9 |
| 1930 | 122.8 | 127.6 | 117.6 |
| 1940 | 131.7 | 151.2 | 137.1 |
| 1950 | 150.7 | 175.7 | 158.4 |
| 1960 | 179.3 | 200.2 | 180.9 |
| 1970 | 203.2 | 223.8 | 204.4 |
| 1980 | 226.5 | 245.7 | 228.3 |
| 1990 | 248.7 | 265.3 | 252.0 |
| 2000 | 281.4 | 282.3 | 275.1 |
| 误差平方和/10000 | 0.2749 | 0.0458 |
模型分析
首先,对于logistic模型,应该给予比较高的评价,该模型在生态系统的种群研究中有很大的价值。该模型对美国人口的趋势预测也比较准确。接下来对于方法一和方法二的分析:从标准差结果可以看的出来,非线性最小二乘法拟合的结果(即方法二)比线性最小二乘法拟合(即方法一)要好,二的标准差控制在6以内,是一个相对准确的结果了。但是就预测的结果来看,在预测2010年美国的人口数量的时候,方法一要更加准确,方法二预测的结果反而比较大了(414.48),是不符合实际的,这里笔者觉得会不会是出现过拟合的现象,又或者是出现了新的影响因素。这可能需要进一步研究。
实验总结
对于建立模型的方法,在本节中,我们可以很清楚地认识到要想建立一个非常接近现实的模型是不简单的,我们最开始需要根据该现实问题最大的影响因数提取出来,其他条件理想化,然后建立起该主要因数影响的模型。再通过逐步添加其他的次要的影响因数,逐步建立起较为完善的模型。
其次,在建立模型的过程,我们也可以用一些比较简单的方程,比如我们在完善logistic模型的时候对于指数部分的拟合,一开始是使用简单的线性拟合,然后再是二次方程拟合,最后又进行非线性最小二乘法拟合,一步步得到比较精确的模型。
判断一个模型的准确程度,用模型来预测一些已知的结果是一种非常好的方式。但是,我们也可以通过改变模型的参数,通过判断模型的变化是否与现实相符,这样一来还可以协助判断某些参数在现实中的意义。
Logistic模型是生物系统中对种群数量进行预测的一个非常经典的模型,通过该模型我们清楚认识到种群数量的增长不是按照指数的增长方式来的,他会有一些限制(包括环境情况,资源等),最后趋向一个平衡。这对我们研究种群的数量变化为人类的生产发展提供参考。同时适用于外来生物入侵的现象,也可以为解决繁殖泛滥的解决方法提供理论基础。
今日的分享就到这里啦,大家有什么想法都可以在评论区讨论~~
每一条我都会很认真看的,谢谢大家~~
参考文献:《数学模型》第五版,姜启源、谢金星、叶俊编,国际标准书号ISBN:9787040496314 第五章:微分方程模型
(本文为原创作品,未经许可禁止转载!)
If you like this blog or find it useful for you, you are welcome to comment on it. You are also welcome to share this blog, so that more people can participate in it. If the images used in the blog infringe your copyright, please contact the author to delete them. Thank you !